Test results and Terraform scripts to come for this post, so stay tuned!
“Ugh, these build times” Link to heading
every developer ever
I have a running joke with one developer at work where whenever we’re both waiting for a deployment out to Integration, and it takes longer than a few minutes, I’ll see those words grace my screen. Sometimes he’ll send it to me on a rather fast build just to piss me off. It’s all in good faith; we’re just joking around…..but I feel his pain.
I think we can all agree that waiting for builds to complete is one of the most frustrating parts of the development process. It sucks just sitting there, waiting for Jenkins to show that magical green checkmark, so you can finally move on to let the development teams know their code broke Integration.
It wasn’t for a lack of trying, though. We’ve migrated our largest applications to Kubernetes over the past year, and the promise of faster builds came with it. Gone were the Ansible playbooks SSHing onto servers at each stage, configuring the whole OS from scratch each time. Instead, now we had the magic of containers and cacheable layers - and it made a difference. Our deployment times went from 20-30 minutes per environment to just 5-10 minutes.
I was overjoyed - I had cut the time in half! Surely that must mean something. And it did - that definitely made the developers happy……
Then I received a message from said unnamed developer one week later.
“Ughh, these build times”

I threw up my hands in disbelief. I had just cut the build time in half! How could they still be complaining? I mean, I get it - it’s not ideal. But it’s a lot better than it was before, right?
Then, I had to change a logger in one of our applications.
“Ughhh, these build times”
It was just a file destination change on a logger. It’s not like I’m changing the entire application; I just needed to go to /var/log/app instead of /var/log. Why is this taking so long…it was just one line of code…
10 minutes later, I was still waiting for the build to complete. I was starting to see my coworker’s point.
“There’s gotta be a better way.” Link to heading
Also every developer ever. Or maybe every project lead. Definitely every architect.
To understand how we could make the builds faster, we have to know how the build system worked previously. Luckily it’s simple enough.
The Current Build System Link to heading
Our current build system is a Jenkins pipeline on a Kubernetes cluster. It’s a reasonably standard Jenkins Kubernetes setup - we have a Jenkins controller running as a StatefulSet with a single pod and a bunch of Jenkins agents that run the builds within the pipelines as Pod Agents. Let’s take into context what happens when a developer merges a PR into the dev branch:
- Jenkins receives a webhook from Bitbucket that a new commit has been pushed to the
devbranch - Jenkins spins up a new Pod Agent to run the non-builder stages of the pipeline, notably the Helm chart for the deployment.
- After prerequisite tasks are completed, the pipeline spins up a Kaniko builder pod to build the Docker image
- The Kaniko pod builds the image, pushes it to the container registry, then terminates
- The pipeline returns to the original pod agent, which then deploys the Helm chart to Integration
- The pipeline terminates, and the pod agent is destroyed
This is a fairly standard (and easy to replicate) setup, as it offers a couple of eases:
- We don’t have to worry about pre-configured agents - we can just spin up a new one for each build
- No need for cleaning up the agent and its filesystem after the build - it’s destroyed automatically
- Initialization of the agents are relatively quick (a few seconds)
However, there are a few downsides to this approach:
- The Kaniko builds only method of layer caching is the container registry, which can be slow if the registry is busy
- Any persistent data (such as the
.m2cache for Maven or thenpmcache for Node) is lost after each build - The Kaniko builds are single-threaded, and that word is a dirty word in the world of parallelization
Clearly, there’s room for improvement here. It is not too efficient to have to throw away your build cache on every run of the pipeline. But how can we improve this?
In comes BuildKit Link to heading
We used Kaniko for the same reason that many people did in the early days of CI/CD on Kubernetes - it was the only thing that worked well. Even though Google said this was an ‘unofficial’ project, it was still the best thing out there. It was a bit slow, but it worked, and it was easy to set up - I remember going through many examples of Argo CD pipelines that used Kaniko as the builder. But the time had come when I was getting dissatisfied with the performance, and I wanted to see if there was anything better out there.
Then it hit me.
Wait, what about the thing my computer is using?
I had never thought to look deeper into Buildkit, but sure enough, there was an entire section in the repo on examples of running Buildkit in K8S. I was intrigued, so I decided to give it a shot by throwing up some builds into builder pods.
After some trial and error (and a couple of hiccups around mount option permissions in Bottlerocket), 5-10 minutes became 3-5 minutes. Quite a remarkable improvement for swapping one shiny tool for another shiny tool. But I wanted more - to see if I could make it even faster.
“Let’s make it even faster.” Link to heading
I started looking at some of the downsides I mentioned earlier. I knew I wasn’t going to be able to do much about changing the concurrency behavior outside of proper multi-staging in the Dockerfile. So, I focused my attention on the other two:
- The Kaniko builds only method of layer caching is the container registry, which can be slow if the registry is busy
- Any persistent data (such as the
.m2cache for Maven or thenpmcache for Node) is lost after each build
If I was going to speed these builds up, I needed a way to persist both of these pieces of data throughout builds through faster means. Let’s start with the first one, as it was the easiest.
Layer Caching Link to heading
As I mentioned, the prior layer caching system left much to be desired. It relied on the registry’s performance, which involved traversal through an extra system as a whole outside the boundary of the CI system. However, it did provide one benefit: the immediately available layer cache. Whatever solution I implemented needed to be compatible with this behavior, as sacrificing the previous build’s layer cache to chance on a node-dependent filesystem cache would be a huge step backward, as these are the larger cache chunks that would kick minutes off build times when they hit.
Buildkit has an experimental S3 caching driver that can be used to store the layer cache. What makes this so great is that S3 is quite a performant object storage system (Grafana Labs even built their entire monitoring systems using S3 for storage, including the index through their BoltDB Shipper algorithm), and thanks to VPC endpoints, we could keep the network traversal short and sweet over the internal AWS network. Considering our EC2 instance sizes, this would equate to a 10Gbps connection to the S3 bucket. Not too shabby.
Upon implementation, we saw a slight improvement in build times, but nothing too crazy. I was hoping for more, but I was happy with the progress. But I still had one more trick up my sleeve, and it was the one I was most excited about.
Persistent Build Mount Cache Link to heading
The docker file reference syntax has a --mount flag that allows you to mount a volume into the build container. This is useful for mounting the Docker socket into the container, so you can build images from within the container. But it also has another use case - mounting a persistent cache into the container.
Using the type=cache option, you can mount a persistent cache into the container and reuse it across builds. For example, take the following simple Dockerfile that you might use to build a React application and serve with Nginx:
FROM node:18-alpine as builder
RUN apk add --no-cache git python make g++
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm ci
COPY . .
RUN npm run build
FROM nginx:1.22-alpine as runner
COPY --from=builder --chown=nginx:nginx /app/dist /usr/share/nginx/html
EXPOSE 80
USER nginx:nginx
This is a fairly standard Dockerfile for a static React application SPA build. It builds the application to static bundles, then copies the build artifacts into an Nginx container to be served. However, if we wanted to speed this up, we could declare the dockerfile syntax at the top and add a cache mount to the npm ci step:
# syntax = docker/dockerfile:1.4
FROM node:18-alpine as builder
RUN apk add --no-cache git python make g++
WORKDIR /app
COPY package.json package-lock.json ./
RUN --mount=type=cache,id=npm,target=/root/.npm npm ci
COPY . .
RUN npm run build
FROM nginx:1.22-alpine as runner
COPY --from=builder --chown=nginx:nginx /app/dist /usr/share/nginx/html
EXPOSE 80
USER nginx:nginx
We can even take this a step further and mount the Alpine package cache into the container as well:
# syntax = docker/dockerfile:1.4
FROM node:18-alpine as builder
RUN --mount=type=cache,target=/var/cache/apk ln -vs /var/cache/apk /etc/apk/cache \
&& apk add --no-cache git python make g++
COPY package.json package-lock.json ./
RUN --mount=type=cache,id=npm,target=/root/.npm \
npm ci
COPY . .
RUN npm run build
FROM nginx:1.22-alpine as runner
COPY \
--from=builder \
--chown=nginx:nginx \
/app/dist /usr/share/nginx/html
EXPOSE 80
USER nginx:nginx
By doing this, we have made all of the previous builds’ NPM and APK caches available for use in the current build. This means that even if an NPM dependency changes in the package.json, the previous npm cache population wouldn’t be for nothing. Running this locally on my computer, I saw massive improvements in build times on subsequent builds. I was excited to see what this would do in the pipeline. However, I needed to solve the issue of the data getting persisted. So without further ado, enter the secret sauce of the new build system:
Buildkit over TCP Link to heading
Buildkit has a feature that allows you to run the Buildkit daemon over TCP. This is useful to us for a few reasons:
- We can delink the build process and agents from the actual container build system, allowing us to change how the build system is implemented
- We can use consistent hashing to determine which build agent to use for a given build, allowing us to persist the cache data on the agent itself, as well as load balance the builds across multiple agents
- The most critical part: we can persist the Buildkit cache mounts on stateful builders
- And another nifty feature: developers can offload their builds from their local machines to the Buildkit service
Buildkit has a great helper script for generating some certificates to get up and running. After some slight tweaks to the manifests, I ended up having a setup that looked like this:
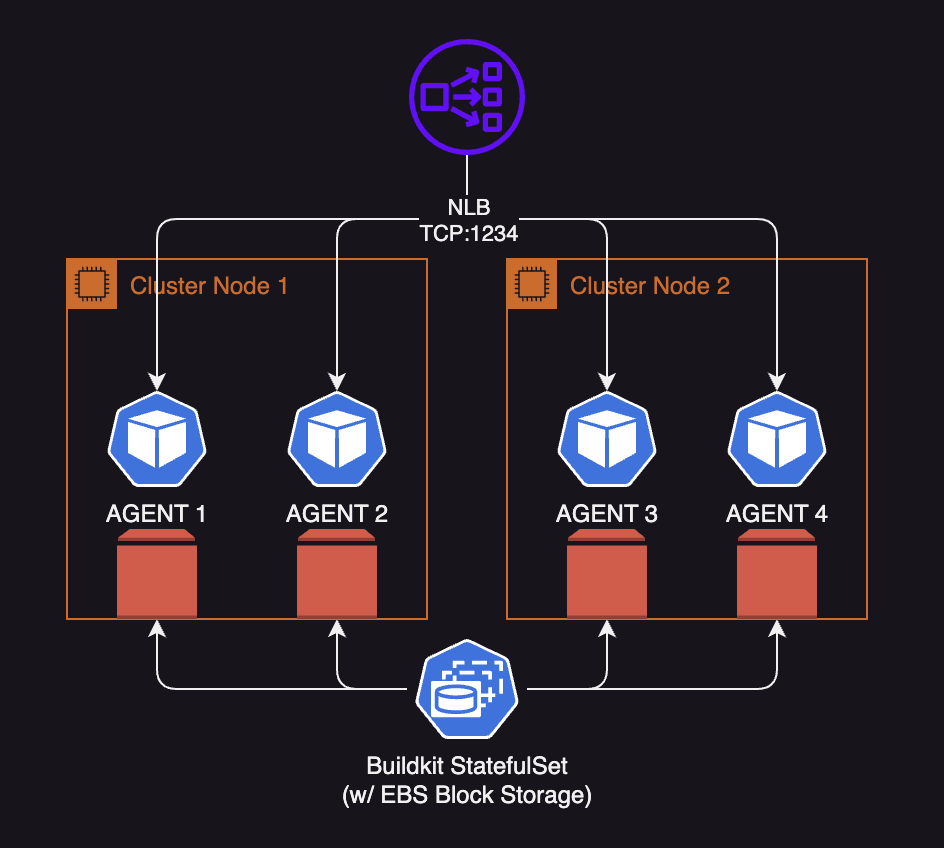
Now, I was able to run the following command to build the above Dockerfile:
buildctl \
--addr tcp://buildkit.joshuapare.com:1234 \
--tlscacert .certs/client/ca.pem \
--tlscert .certs/client/cert.pem \
--tlskey .certs/client/key.pem \
build --frontend dockerfile.v0 --local context=. --local dockerfile=. --target=runner
After a few builds, my jaw dropped.
43 seconds.
That’s how long it took to do a full build of the application after the cache was populated, including in it a dummy code-level and package-level change. The same build on Kaniko took anywhere between 5-10 minutes.
I was blown away. I immediately went and showed my coworker the results.
His response?
“Ugh, these build times”
I guess you can’t please everyone.